
Execute on Airflow#
It's also possible to schedule pipelines for execution by compiling them to a format that can be understood by a third-party scheduling system, and then defining schedules within that system.
This is the approach we use to deploy Dagster pipelines to Airflow (using the dagster-airflow package).
We don't recommend deploying Dagster pipelines to Airflow in greenfield installations. (We recommend the built-in scheduler and partition system for scheduling pipelines, and the Celery-based executor for large-scale deployments.) But if you have a large existing Airflow install, this integration will allow you to follow an incremental adoption path.
Requirements#
You'll need an existing Airflow installation, and to install the
dagster-airflow library into the Python environments in which your
Airflow webserver and worker run.
pip install dagster-airflow
You'll also need to make sure that the Dagster pipeline you want to run using Airflow is available in the Python environments in which your Airflow webserver and worker run.
Overview#
A Dagster pipeline is first compiled with a set of config options into an execution plan, and then the individual execution steps are expressed as Airflow tasks using one of a set of custom wrapper operators (the same operator is used for each task in the DAG) . The resulting DAG can be deployed to an existing Airflow install and scheduled and monitored using all the tools being used for existing Airflow pipelines.
We support two modes of execution (each of which uses its own operator):
- Uncontainerized [Default]: Tasks are invoked directly on the Airflow executors.
- Containerized: Tasks are executed in Docker containers.
Quickstart#
For this quickstart, we'll use our familiar, simple demo pipeline:
import csv
from dagster import pipeline, solid
from dagster.utils import file_relative_path
@solid
def hello_cereal(context):
dataset_path = file_relative_path(__file__, "cereal.csv")
context.log.info(dataset_path)
with open(dataset_path, "r") as fd:
cereals = [row for row in csv.DictReader(fd)]
context.log.info(
"Found {n_cereals} cereals".format(n_cereals=len(cereals))
)
@pipeline
def hello_cereal_pipeline():
hello_cereal()
To compile this existing pipeline to Airflow, we'll use the
dagster-airflow CLI tool. By default, this tool will write the
Airflow-compatible DAG scaffold out to $AIRFLOW_HOME/dags.
dagster-airflow scaffold \
--module-name docs_snippets.docs_snippets.intro_tutorial.airflow \
--pipeline-name hello_cereal_pipeline
Wrote DAG scaffold to file: $AIRFLOW_HOME/dags/hello_cereal_pipeline.py
Let's take a look at the generated file:
"""
The airflow DAG scaffold for docs_snippets.intro_tutorial.airflow.hello_cereal_pipeline
Note that this docstring must contain the strings "airflow" and "DAG" for
Airflow to properly detect it as a DAG
See: http://bit.ly/307VMum
"""
import datetime
import yaml
from dagster_airflow.factory import make_airflow_dag
################################################################################
# #
# # This environment is auto-generated from your configs and/or presets
# #
################################################################################
ENVIRONMENT = """
intermediate_storage:
filesystem:
config:
base_dir: /tmp/dagster-airflow/hello_cereal_pipeline
"""
################################################################################
# #
# # NOTE: these arguments should be edited for your environment
# #
################################################################################
DEFAULT_ARGS = {
"owner": "airflow",
"depends_on_past": False,
"start_date": datetime.datetime(2019, 11, 7),
"email": ["airflow@example.com"],
"email_on_failure": False,
"email_on_retry": False,
}
dag, tasks = make_airflow_dag(
# NOTE: you must ensure that docs_snippets.intro_tutorial.airflow is
# installed or available on sys.path, otherwise, this import will fail.
module_name="docs_snippets.intro_tutorial.airflow",
pipeline_name="hello_cereal_pipeline",
run_config=yaml.safe_load(ENVIRONMENT),
dag_kwargs={"default_args": DEFAULT_ARGS, "max_active_runs": 1},
)
This is a fairly straightforward file with four parts.
First, we import the basic prerequisites to define our DAG (and also make sure that the string "DAG" appears in the file, so that the Airflow webserver will detect it).
Second, we define the config that Dagster will compile our pipeline against. Unlike Dagster pipelines, Airflow DAGs can't be parameterized dynamically at execution time, so this config is static after it's loaded by the Airflow webserver.
Third, we set the DEFAULT_ARGS that will be passed down as the
default_args argument to the airflow.DAG
constructor.
Finally, we define the DAG and its constituent tasks using make_airflow_dag.
If you run this code interactively, you'll see that dag
and tasks are ordinary Airflow objects, just as you'd expect to see
when defining an Airflow pipeline manually:
>>> dag
<DAG: hello_cereal_pipeline>
>>> tasks
[<Task(DagsterPythonOperator): hello_cereal>]
Within this Airflow DAG, DagsterPythonOperator represent
individual execution steps in the Dagster pipeline.
You can now edit this file, supplying the appropriate environment
configuration and Airflow DEFAULT_ARGS for your particular Airflow
instance. When Airflow sweeps this directory looking for DAGs, it will
find and execute this code, dynamically creating an Airflow DAG and
steps corresponding to your Dagster pipeline.
Note that an extra storage parameter will be injected into your
run config if it is not set. By default, this will use filesystem
storage, but if your Airflow executors are running on multiple nodes,
you will need either to configure this to point at a network filesystem,
or consider an alternative such as S3 or GCS storage.
You will also need to make sure that all of the Python and system requirements that your Dagster pipeline requires are available in your Airflow execution environment; e.g., if you're running Airflow on multiple nodes with Celery, this will be true for the Airflow master and all workers.
You will also want to make sure you have a process in place to update your Airflow DAGs, as well as the Dagster code available to the Airflow workers, whenever your pipelines change.
Using Presets#
The Airflow scaffold utility also supports using presets when generating an Airflow DAG:
pip install -e dagster/python_modules/dagster-test
dagster-airflow scaffold \
--module-name dagster_test.toys.error_monster \
--pipeline-name error_monster \
--preset passing
Running a pipeline on Airflow#
Ensure that the Airflow webserver, scheduler (and any workers
appropriate to the executor you have configured) are running. The
dagster-airflow CLI tool will automatically put the generated DAG
definition in $AIRLFLOW_HOME/dags, but if you have a different setup,
you should make sure that this file is wherever the Airflow webserver
looks for DAG definitions.
When you fire up the Airflow UI, you should see the new DAG:
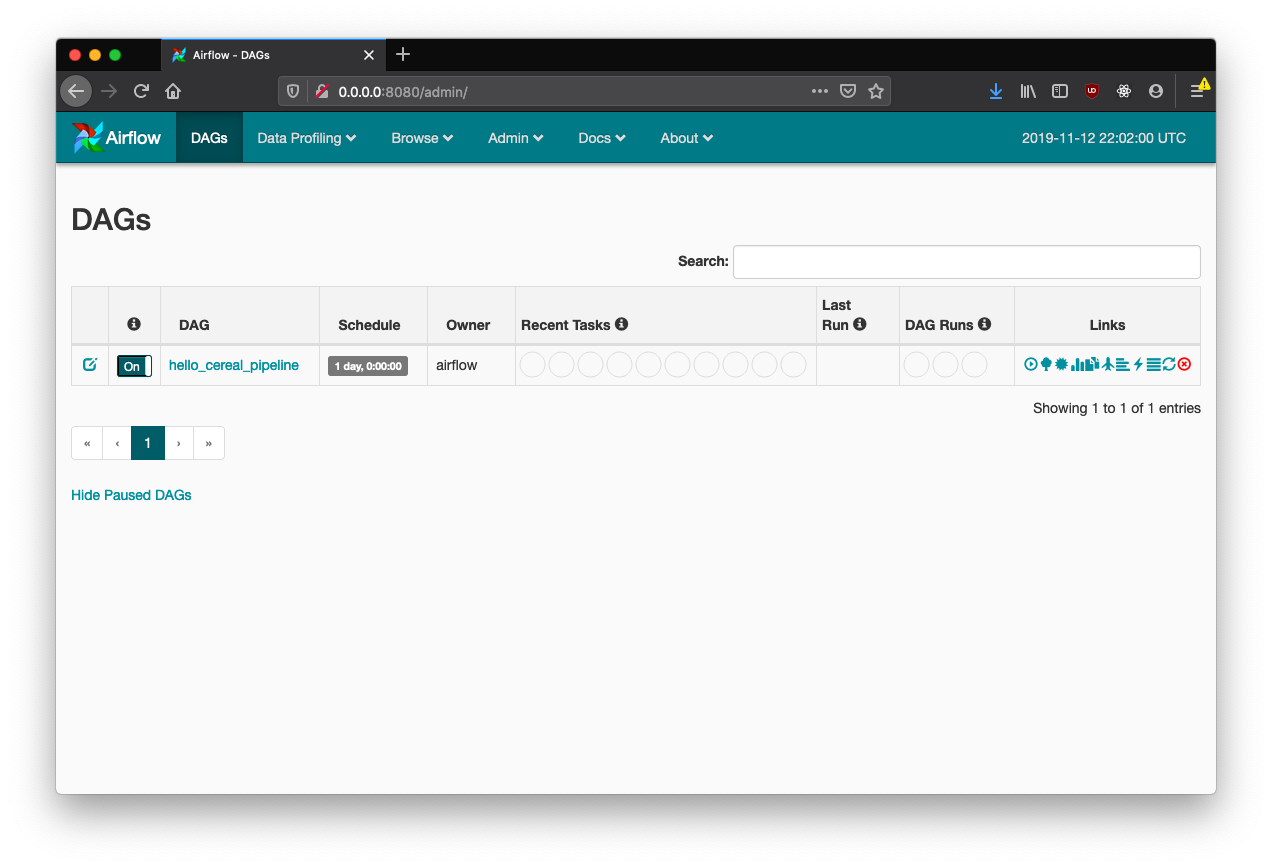
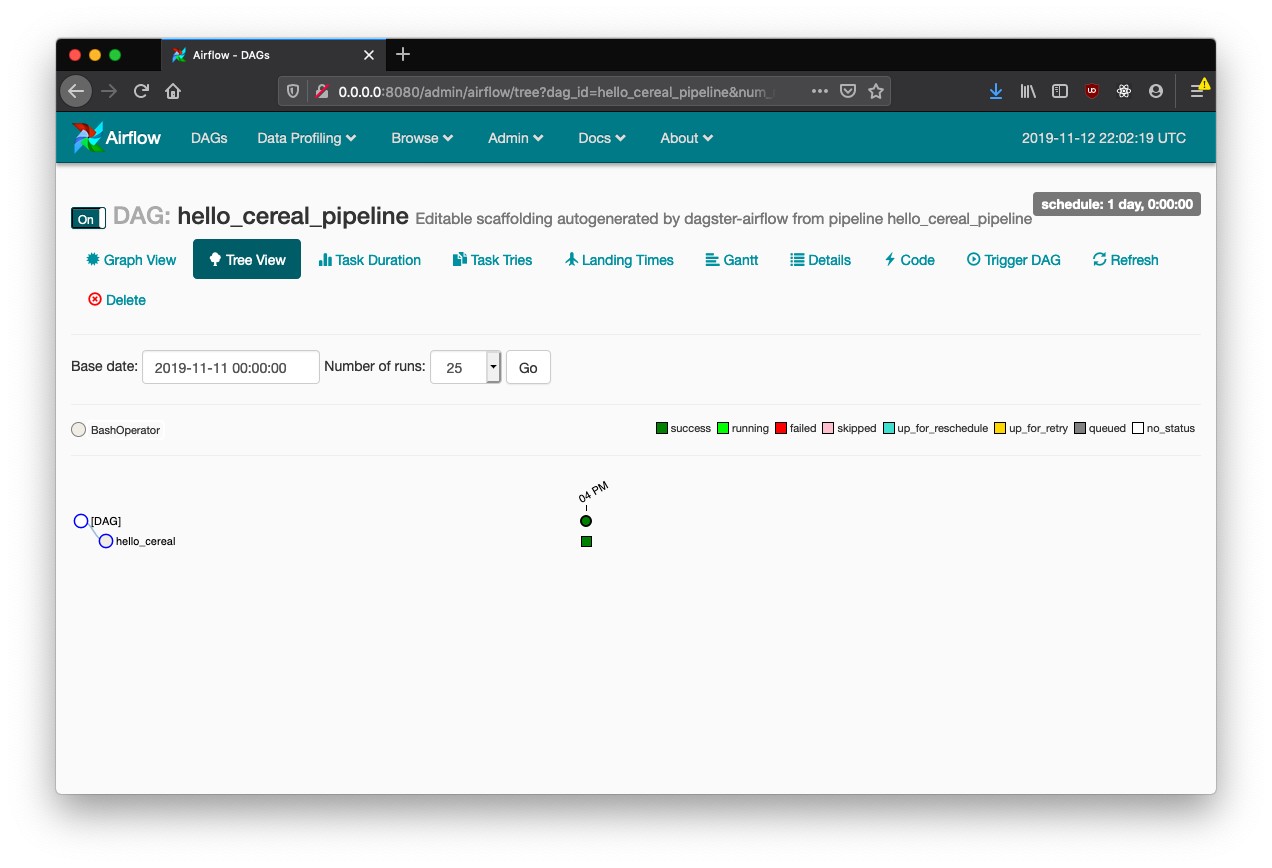
Kick off a run manually, and you'll be able to use the ordinary views of the pipeline's progress:
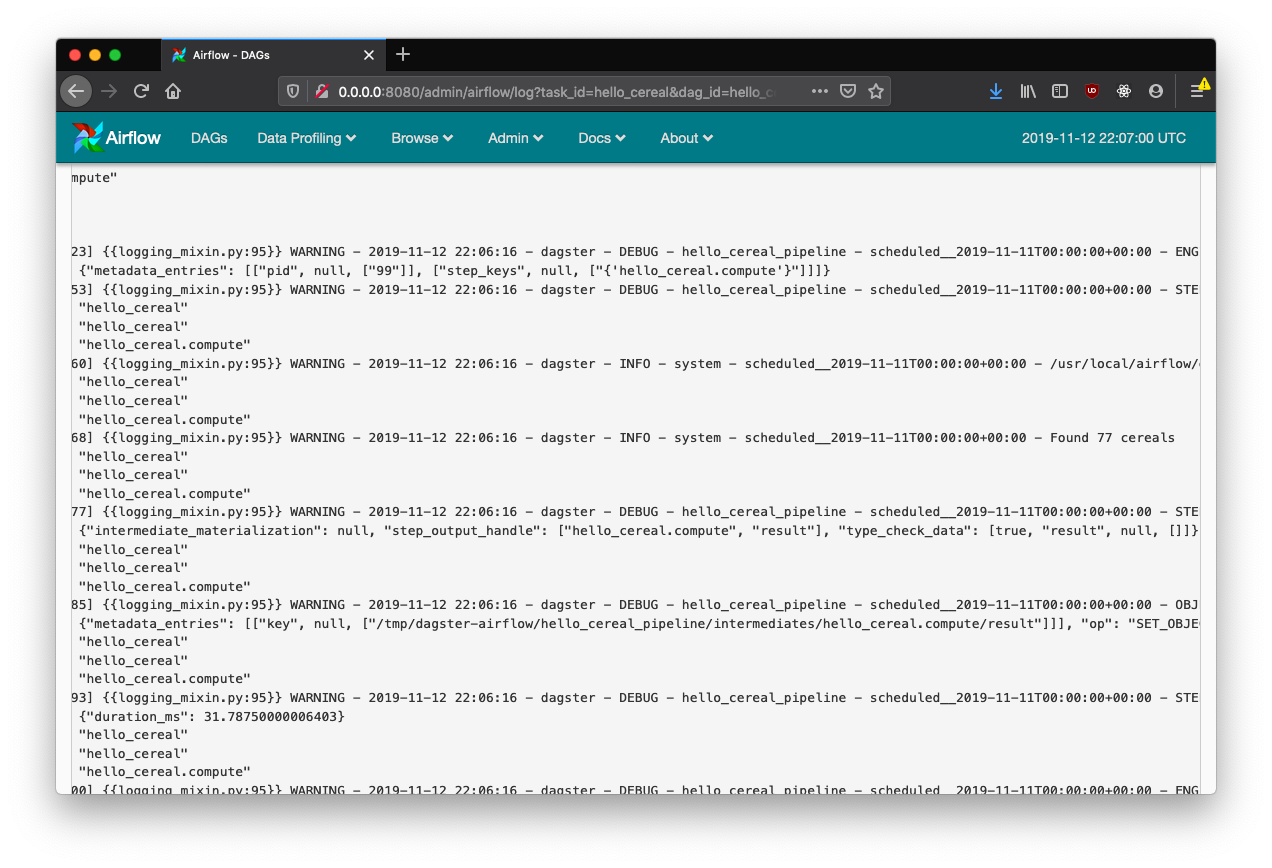
And logs will be available in the Airflow log viewer:
Running Containerized#
Running containerized, we use a DagsterDockerOperator to wrap Dagster pipelines.
In order to run containerized Dagster pipelines, you must have Docker
running in your Airflow environment (just as with the ordinary Airflow DockerOperator).
Running in a containerized context requires a persistent intermediate storage layer available to the Dagster containers, such as a network filesystem, S3, or GCS.
You'll also need to containerize your Dagster repository.
Containerizing a Dagster repository#
Make sure you have Docker installed, and write a Dockerfile like the following:
# You may use any base container with a supported Python runtime: 2.7, 3.5, 3.6, or 3.7
FROM python:3.7
# Install any OS-level requirements (e.g. using apt, yum, apk, etc.) that the pipelines in your
# repository require to run
# RUN apt-get install some-package some-other-package
# Set environment variables that you'd like to have available in the built image.
# ENV IMPORTANT_OPTION=yes
# If you would like to set secrets at build time (with --build-arg), set args
# ARG super_secret
# Install dagster_graphql
RUN pip install dagster_graphql
# Install any Python requirements that the pipelines in your repository require to run
ADD /path/to/requirements.txt .
RUN pip install -r requirements.txt
# Add your workspace.yaml file so that dagster_graphql knows where to look to find your repository,
# the Python file in which your repository is defined, and any local dependencies (e.g., unpackaged
# Python files from which your repository definition imports, or local packages that cannot be
# installed using the requirements.txt).
ADD /path/to/workspace.yaml .
ADD /path/to/repository_definition.py .
# ADD /path/to/additional_file.py .
# The dagster-airflow machinery will use dagster_graphql to execute steps in your pipelines, so we
# need to run dagster_graphql when the container starts up
ENTRYPOINT [ "dagster_graphql" ]
Of course, you may expand on this Dockerfile in any way that suits your needs.
Once you've written your Dockerfile, you can build your Docker image.
You'll need the name of the Docker image (-t) that contains your
repository later so that the docker-airflow machinery knows which image
to run. E.g., if you want your image to be called
dagster-airflow-demo-repository:
docker build -t dagster-airflow-demo-repository -f /path/to/Dockerfile .
If you want your containerized pipeline to be available to Airflow operators running on other machines (for example, in environments where Airflow workers are running remotely) you'll need to push your Docker image to a Docker registry so that remote instances of Docker can pull the image by name, or otherwise ensure that the image is available on remote nodes.
For most production applications, you'll probably want to use a private Docker registry, rather than the public DockerHub, to store your containerized pipelines.
Defining your pipeline as a containerized Airflow DAG#
As in the uncontainerized case, you'll put a new Python file defining your DAG in the directory in which Airflow looks for DAGs.
from dagster_airflow.factory import make_airflow_dag_containerized
from my_package import define_my_pipeline
pipeline = define_my_pipeline()
image = 'dagster-airflow-demo-repository'
dag, steps = make_airflow_dag_containerized(
pipeline,
image,
run_config={'storage': {'filesystem': {'config': {'base_dir': '/tmp'}}}},
dag_id=None,
dag_description=None,
dag_kwargs=None,
op_kwargs=None
)
You can pass op_kwargs through to the the DagsterDockerOperator to
use custom TLS settings, the private registry of your choice, etc., just as you would
configure the ordinary Airflow DockerOperator.
Docker bind-mount for filesystem intermediate storage#
By default, the DagsterDockerOperator
will bind-mount /tmp on the host into /tmp in the Docker container.
You can control this by setting the op_kwargs in make_airflow_dag.
For instance, if you'd prefer to mount /host_tmp on the host into
/container_tmp in the container, and use this volume for intermediate
storage, you can run:
dag, steps = make_airflow_dag(
pipeline,
image,
run_config={'storage': {'filesystem': {'config' : {'base_dir': '/container_tmp'}}}},
dag_id=None,
dag_description=None,
dag_kwargs=None,
op_kwargs={'host_tmp_dir': '/host_tmp', 'tmp_dir': '/container_tmp'}
)
Compatibility#
Note that Airflow versions less than 1.10.3 are incompatible with Python 3.7+.