Advanced: Materializations#
Steps in a data pipeline often produce persistent artifacts, for instance, graphs or tables describing the result of some computation. Typically these artifacts are saved to disk (or to cloud storage) with a name that has something to do with their origin. But it can be hard to organize and cross-reference artifacts produced by many different runs of a pipeline, or to identify all of the files that might have been created by some pipeline's logic.
Dagster solids can describe their persistent artifacts to the system by
yielding AssetMaterialization events. Like TypeCheck and ExpectationResult,
asset materializations are side-channels for metadata -- they don't get passed
to downstream solids and they aren't used to define the data dependencies that
structure a pipeline's DAG.
Suppose that we rewrite our sort_calories solid so that it saves
the newly sorted data frame to disk.
@solid
def sort_by_calories(context, cereals):
sorted_cereals = sorted(
cereals, key=lambda cereal: int(cereal["calories"])
)
context.log.info(
"Least caloric cereal: {least_caloric}".format(
least_caloric=sorted_cereals[0]["name"]
)
)
context.log.info(
"Most caloric cereal: {most_caloric}".format(
most_caloric=sorted_cereals[-1]["name"]
)
)
fieldnames = list(sorted_cereals[0].keys())
sorted_cereals_csv_path = os.path.abspath(
"output/calories_sorted_{run_id}.csv".format(run_id=context.run_id)
)
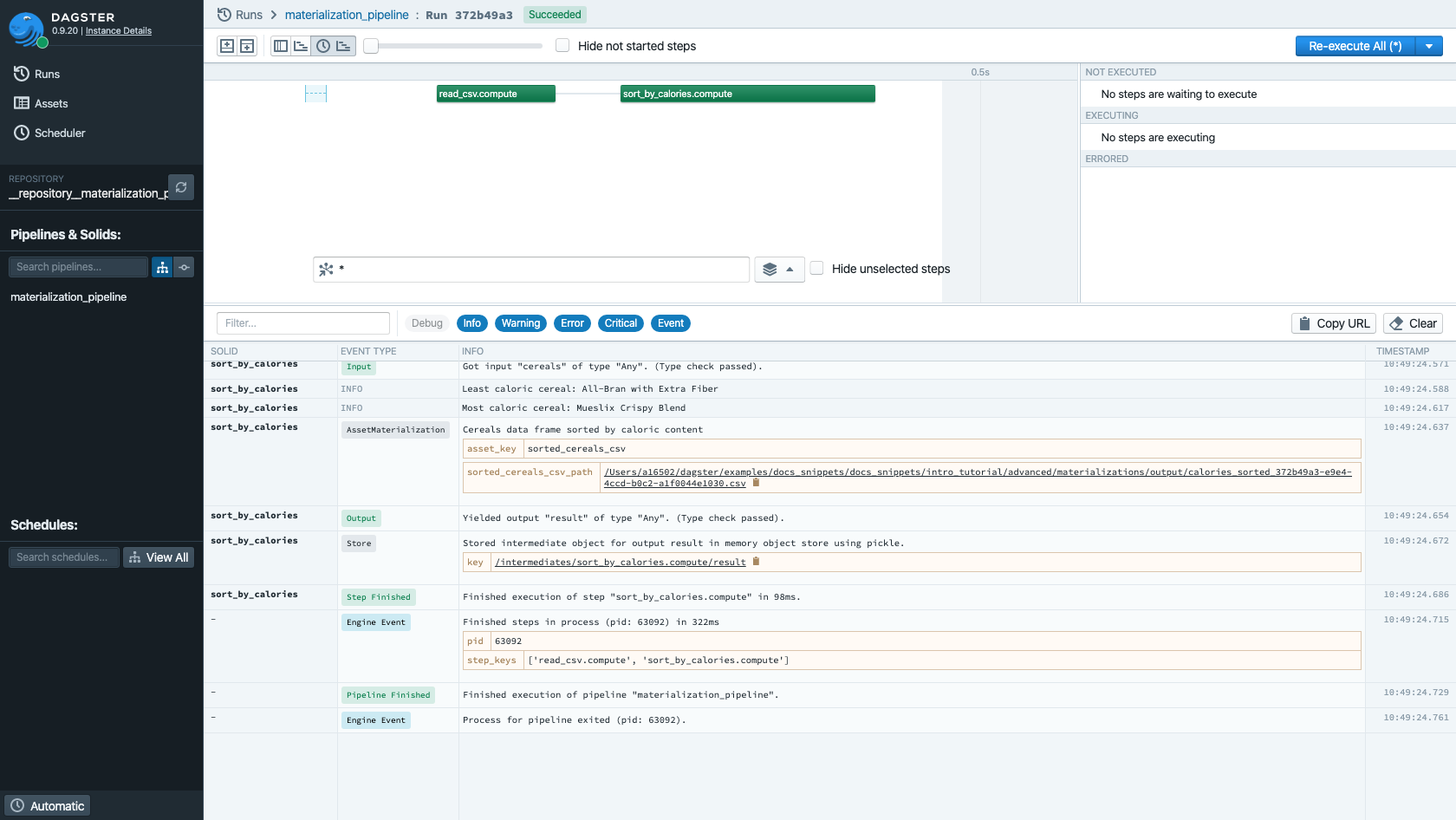
We've taken the basic precaution of ensuring that the saved csv file has a different filename for each run of the pipeline. But there's no way for Dagit to know about this persistent artifact. So we'll add the following lines:
@solid
def sort_by_calories(context, cereals):
sorted_cereals = sorted(
cereals, key=lambda cereal: int(cereal["calories"])
)
context.log.info(
"Least caloric cereal: {least_caloric}".format(
least_caloric=sorted_cereals[0]["name"]
)
)
context.log.info(
"Most caloric cereal: {most_caloric}".format(
most_caloric=sorted_cereals[-1]["name"]
)
)
fieldnames = list(sorted_cereals[0].keys())
sorted_cereals_csv_path = os.path.abspath(
"output/calories_sorted_{run_id}.csv".format(run_id=context.run_id)
)
os.makedirs(os.path.dirname(sorted_cereals_csv_path), exist_ok=True)
with open(sorted_cereals_csv_path, "w") as fd:
writer = csv.DictWriter(fd, fieldnames)
writer.writeheader()
writer.writerows(sorted_cereals)
yield AssetMaterialization(
asset_key="sorted_cereals_csv",
description="Cereals data frame sorted by caloric content",
metadata_entries=[
EventMetadataEntry.path(
sorted_cereals_csv_path, "sorted_cereals_csv_path"
)
],
)
yield Output(None)
Note that we've had to add the last line, yielding an Output.
Until now, all of our solids have relied on Dagster's implicit conversion
of the return value of a solid's compute function into its output. When we explicitly
yield other types of events from solid logic, we need to also explicitly yield
the output so that the framework can recognize them.
Now, if we run this pipeline in Dagit:
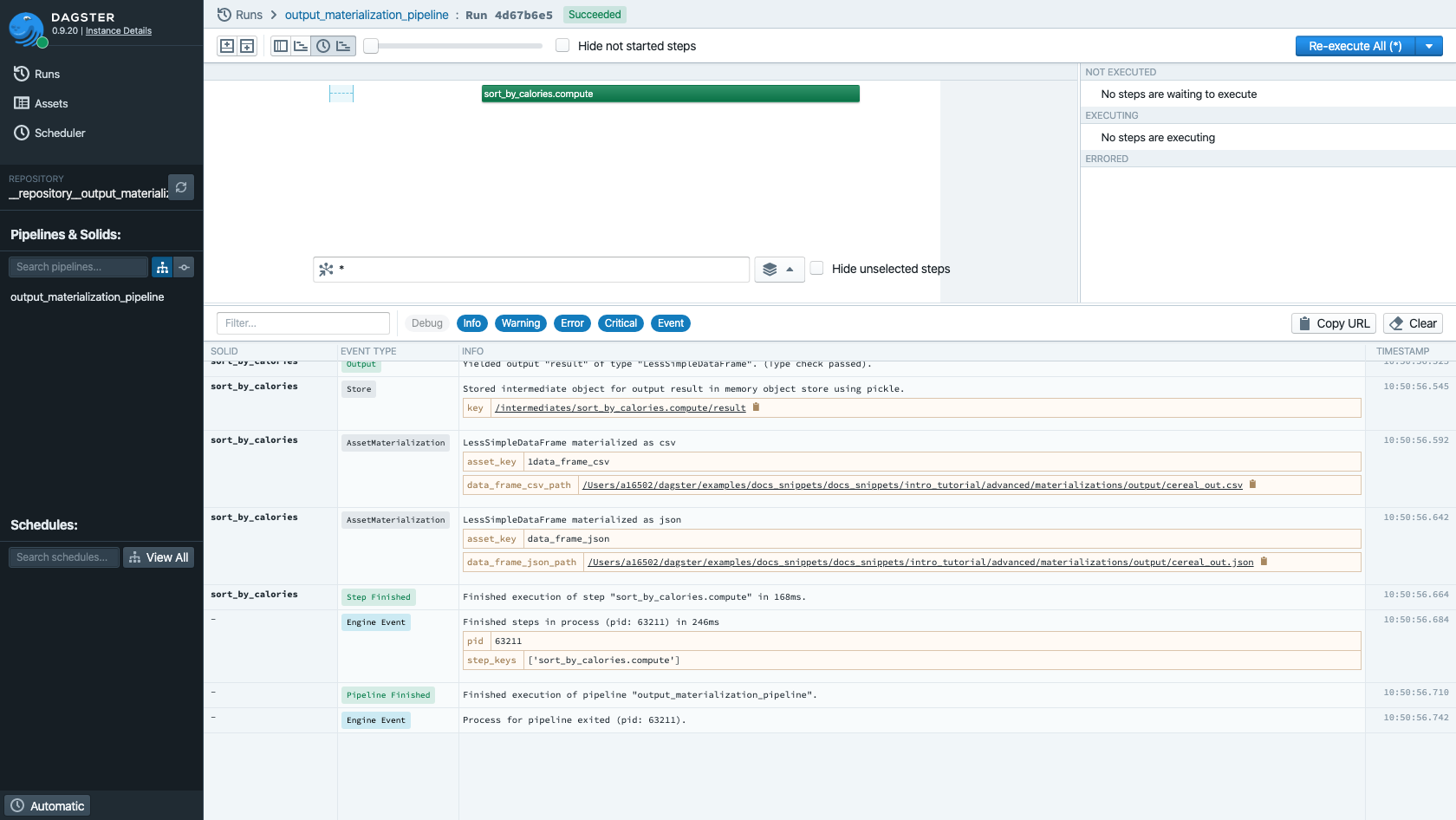
Custom Materializing Data Types#
Data types can also be configured so that outputs materialize themselves,
obviating the need to explicitly yield an AssetMaterialization from solid logic.
Dagster calls this facility the @dagster_type_materializer.
Suppose we would like to be able to configure outputs of our toy custom type,
the SimpleDataFrame, to be automatically materialized to disk as
both as a pickle and as a .csv. (This is a reasonable idea, since .csv files
are human-readable and manipulable by a wide variety of third party tools,
while pickle is a binary format.)
@dagster_type_materializer(
{
"csv": Field(
{
"path": String,
"sep": Field(String, is_required=False, default_value=","),
},
is_required=False,
),
"json": Field(
{
"path": String,
},
is_required=False,
),
}
)
def less_simple_data_frame_materializer(context, config, value):
# Materialize LessSimpleDataFrame into a csv file
csv_path = os.path.join(
os.path.dirname(__file__), os.path.abspath(config["csv"]["path"])
)
os.makedirs(os.path.dirname(csv_path), exist_ok=True)
with open(csv_path, "w") as fd:
fieldnames = list(value[0].keys())
writer = csv.DictWriter(
fd, fieldnames, delimiter=config["csv"]["sep"]
)
writer.writeheader()
writer.writerows(value)
context.log.debug(
"Wrote dataframe as .csv to {path}".format(path=csv_path)
)
yield AssetMaterialization(
"1data_frame_csv",
"LessSimpleDataFrame materialized as csv",
[
EventMetadataEntry.path(
path=csv_path,
label="data_frame_csv_path",
description="LessSimpleDataFrame written to csv format",
)
],
)
# Materialize LessSimpleDataFrame into a json file
json_path = os.path.abspath(config["json"]["path"])
with open(json_path, "w") as fd:
json_value = seven.json.dumps([dict(row) for row in value])
fd.write(json_value)
context.log.debug(
"Wrote dataframe as .json to {path}".format(path=json_path)
)
yield AssetMaterialization(
"data_frame_json",
"LessSimpleDataFrame materialized as json",
[
EventMetadataEntry.path(
path=json_path,
label="data_frame_json_path",
description="LessSimpleDataFrame written to json format",
)
],
)
We set the output materialization config on the type:
@usable_as_dagster_type(
name="LessSimpleDataFrame",
description="A more sophisticated data frame that type checks its structure.",
loader=less_simple_data_frame_loader,
materializer=less_simple_data_frame_materializer,
)
class LessSimpleDataFrame(list):
pass
Now we can tell Dagster to materialize outputs of this type by providing config:
solids:
sort_by_calories:
inputs:
cereals:
csv_path: "cereal.csv"
outputs:
- result:
csv:
path: "output/sorted_cereals.csv"
sep: ";"
When we run this pipeline, we'll see that asset materializations are yielded (and visible in the structured logs in Dagit), and that files are created on disk (with the semicolon separator we specified).